Insights · 2026-03-03
Qwen 3.5: Why Small Local Models Are Changing the Cloud AI Calculus for SMEs

🖥️ Local AI infrastructure: data control, cost predictability, GDPR compliance without extra work
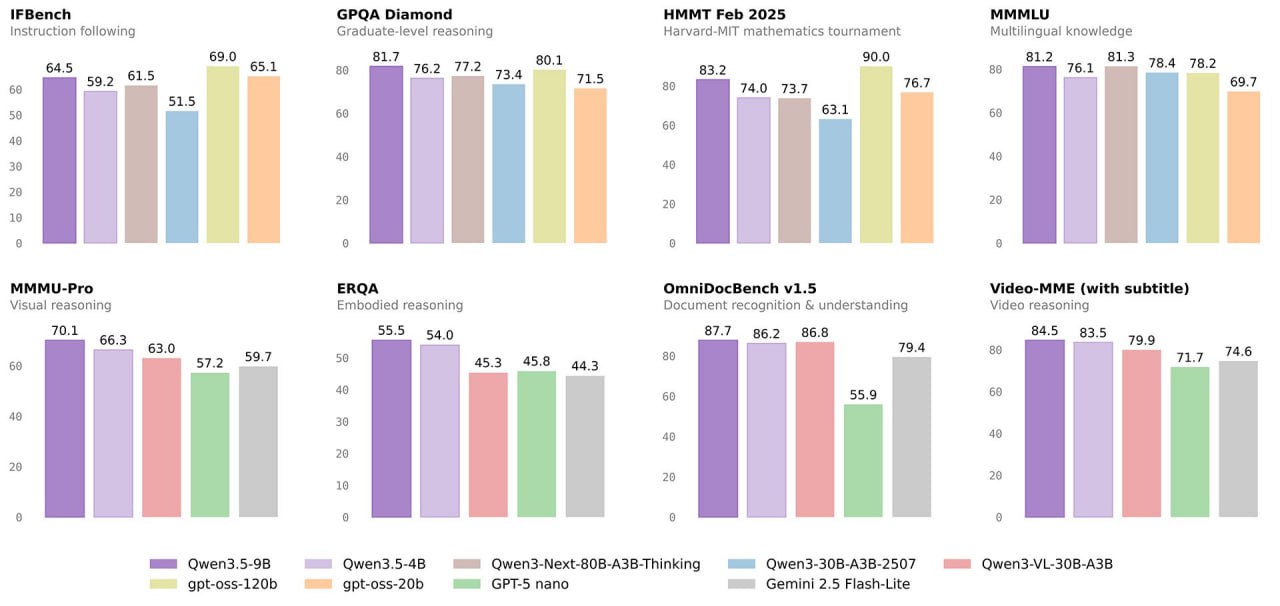
A 9-billion-parameter model that runs on a Mac mini — and outperforms OpenAI's 120-billion-parameter gpt-oss-120B on key benchmarks. That's Qwen 3.5, released by Alibaba's Qwen team on March 2, 2026, under an Apache 2.0 license.
This isn't a footnote. It's a shift that forces a harder look at the "cloud or local?" question for a large class of internal business workflows.
What Qwen 3.5 actually delivers
The Qwen3.5 Small Series covers four models: 0.8B, 2B, 4B, and 9B parameters. All four run locally, all four are natively multimodal, all four support up to 262,144 tokens of context.
The key number is the performance-to-footprint ratio. Qwen3.5-9B outperforms OpenAI's gpt-oss-120B on multilingual knowledge and graduate-level reasoning benchmarks — at 13.5× smaller model size. On Video-MME (with subtitles), the 9B variant scores 84.5; Google's Gemini 2.5 Flash-Lite scores 74.6.
Technically, Qwen 3.5 uses a hybrid architecture combining Gated Delta Networks (linear attention) with sparse Mixture-of-Experts. This reduces memory pressure and increases inference throughput — both directly relevant to running production AI on office-grade hardware without a data center.
The model runs today on standard laptops. On a Mac mini M4, it's production-capable.
What this means for law firms, practices, and SMBs
The logic until recently was straightforward: cloud AI is stronger, so you use cloud AI — and accept that data leaves your premises. For teams handling client data, patient records, or sensitive business information, that was always an uncomfortable trade.
Qwen 3.5 changes this for a specific, well-defined workload type: routine internal tasks involving sensitive data.
Concretely:
- 📄Document drafts and template generation from your own files: no external API, no per-token cost
- 📬Inbox triage and prioritization: classify incoming emails without sending their contents to a third-party server
- 📋Document summarization: contracts, reports, meeting notes — processed locally, GDPR-compliant without extra effort
- 🔍Internal search and knowledge queries via RAG over your own document store
For all of this, a 9B model is sufficient. It doesn't need to produce novel legal strategy or handle complex open-ended research — it needs to reliably process standard tasks without data leaving the building.
Hardware reality: what "local" actually means today
"Local" used to imply a server room and an IT team. That's no longer the default scenario.
Mac mini M4
Entryfrom ~€1,500 list price
For teams with 1–5 concurrent users: the simplest production entry point. Qwen3.5-9B runs stably, and inference speed is practical for office tasks. No fan noise, no separate server hardware.
Mac Studio M4 Ultra
Scalefrom ~€5,000
For teams with higher concurrency or who want to run larger models (27B+). Up to 192 GB Unified Memory — for more demanding workloads.
NVIDIA GPU servers
Enterprisefrom ~€8,000+
For Linux infrastructure and maximum model flexibility. For most law firms and practices, not a sensible entry point.
The right choice depends on your specific workload. A hardware calculator helps calibrate this without needing a consultation call.
When cloud AI still makes sense
To be direct: cloud models are not obsolete. They remain the better choice when:
- Peak loads are unpredictable and local hardware would be saturated
- Tasks are complex and infrequent — uncommon legal research involving new case law, complex strategic analysis, translation into rare languages
- No sensitive data is involved — publicly available content, marketing copy, general research
- The team has no interest in running infrastructure and is prepared to consciously accept the compliance trade-offs
The decision isn't cloud-or-local. It's: which workload type belongs on which infrastructure?
Many teams will do well with a hybrid approach: sensitive routine tasks handled locally, peak loads and complex edge cases routed through cloud APIs — with carefully anonymized or synthetic data.
Benchmark Snapshot: Qwen 3.5 at a glance
The actual shift
Until recently, "local" wasn't a realistic option for most SMBs. Models were either too weak or too large for available hardware. You either needed data-center hardware or accepted quality compromises.
Qwen 3.5 is one point in a trend line that's moving quickly. A 9B model outperforming a 120B model — on a device that fits on any desk.
For teams with confidential data, predictable workloads, and an interest in cost control, this is now a serious option — not a hobbyist project.
Next step
What does local AI infrastructure cost for your team?
Before deciding, run a concrete calculation: what does local infrastructure cost for your team — compared to ongoing API spend?