Einblicke · 2026-03-03
Qwen 3.5: Warum kleine lokale Modelle die Cloud-KI-Kalkulation kippen

🖥️ Lokale KI-Infrastruktur: Kontrolle, Kostenprediktabilität, DSGVO-Konformität ohne Extra-Aufwand
Ein 9-Milliarden-Parameter-Modell, das auf einem Mac mini läuft — und dabei OpenAIs 120-Milliarden-Parameter-Modell auf zentralen Benchmarks schlägt. Das ist Qwen 3.5, veröffentlicht von Alibabas Qwen-Team am 2. März 2026 unter Apache-2.0-Lizenz.
Das ist keine Randnotiz. Das ist eine Verschiebung, die die Frage „Cloud oder lokal?" für viele interne Unternehmensworkflows neu beantwortet.
Was Qwen 3.5 konkret leistet
Die Qwen3.5-Small-Serie umfasst vier Modelle: 0,8B, 2B, 4B und 9B Parameter. Alle vier laufen lokal, alle vier sind multimodal, alle vier verarbeiten bis zu 262.144 Tokens Kontext.
Entscheidend ist das Verhältnis von Leistung zu Aufwand. Das Qwen3.5-9B-Modell übertrifft OpenAIs gpt-oss-120B auf mehrsprachigen Wissens- und Reasoning-Benchmarks — bei 13,5× kleinerem Modell. Auf dem Video-MME-Benchmark (mit Untertiteln) erreicht die 9B-Variante 84,5 Punkte; zum Vergleich: Googles Gemini 2.5 Flash-Lite liegt bei 74,6.
Technisch setzt Qwen 3.5 auf eine Hybridarchitektur aus Gated Delta Networks (lineare Attention) und sparsem Mixture-of-Experts. Das reduziert den Speicherbedarf und steigert den Inference-Durchsatz — beides direkt relevant für den Betrieb auf Unternehmenshardware ohne Rechenzentrum.
Das Modell läuft heute auf Standard-Laptops. Auf einem Mac mini M4 ist es produktionsfähig.
Was das für Kanzleien, Praxen und KMU bedeutet
Die Logik bisher war simpel: Cloud-KI ist stärker, also nutzt man Cloud-KI — und akzeptiert, dass Daten das Haus verlassen. Für Teams, die mit Mandantendaten, Patientendaten oder vertraulichen Geschäftsinformationen arbeiten, war das immer eine unbehagliche Kompromisssituation.
Qwen 3.5 verändert diese Kalkulation für einen klar definierten Workload-Typ: routinemäßige, interne Aufgaben mit sensiblen Daten.
Das sind konkret:
- 📄Briefvorlagen und Schriftsatz-Entwürfe aus eigenen Dokumenten: kein externer Zugriff, keine API-Kosten pro Token
- 📬Postfach-Triage und Priorisierung: eingehende E-Mails klassifizieren, ohne Inhalte an Dritte zu übermitteln
- 📋Dokumentenzusammenfassungen: Verträge, Berichte, Aktenvermerke — lokal verarbeitet, DSGVO-konform ohne weiteren Aufwand
- 🔍Interne Suche und Wissensabfragen via RAG über eigene Dokumente
Für all das reicht ein 9B-Modell. Es muss keine komplexen Rechtsanalysen leisten oder neue juristische Strategien entwickeln — es muss verlässlich und schnell Standardaufgaben bearbeiten, ohne dass Daten das Unternehmen verlassen.
Hardware-Realität: Was lokal wirklich bedeutet
„Lokal" klingt nach Serverraum und IT-Abteilung. Das ist heute nicht mehr der Standard.
Mac mini M4
Einstiegab ~1.500 € Listenpreis
Für Teams mit 1–5 parallelen Nutzern: einfachste Einstiegsoption. Qwen3.5-9B läuft stabil, Inferenzgeschwindigkeit ist für Büroaufgaben praxistauglich. Keine Lüfterlast, kein separater Server.
Mac Studio M4 Ultra
Skalierungab ~5.000 €
Für Teams mit höherem gleichzeitigem Anfragevolumen oder für größere Modelle (27B+). Bis zu 192 GB Unified Memory — für anspruchsvollere Workloads.
NVIDIA GPU-Server
Enterpriseab ~8.000 € aufwärts
Für Linux-Infrastruktur und maximale Modellflexibilität. Für die meisten Kanzleien und Praxen kein sinnvoller Einstieg.
Die richtige Wahl hängt vom konkreten Workload ab. Ein Hardware-Rechner hilft bei der Kalibrierung — ohne Beratungstermin.
Wann Cloud-KI weiterhin sinnvoll bleibt
Klar formuliert: Cloud-Modelle sind nicht obsolet. Sie sind die bessere Wahl, wenn:
- Spitzenlasten unberechenbar sind und lokale Hardware ausgelastet würde
- Aufgaben komplex und selten sind — seltene juristische Recherchen mit neuem Fallrecht, komplexe strategische Analysen, Übersetzungen in seltene Sprachen
- Keine sensiblen Daten involviert sind — öffentlich zugängliche Inhalte, Marketing-Texte, allgemeine Recherchen
- Das Team kein Interesse an IT-Betrieb hat und bereit ist, Compliance-Risiken bewusst zu tragen
Die Entscheidung ist nicht Cloud-oder-lokal. Sie ist: welcher Workload-Typ kommt auf welche Infrastruktur?
Viele Teams werden gut fahren mit einem hybriden Ansatz: sensible Routinetasks lokal, Spitzenlast und komplexe Sonderfälle via Cloud — mit sorgfältig anonymisierten oder synthetischen Daten.
Benchmark-Snapshot: Qwen 3.5 im Vergleich
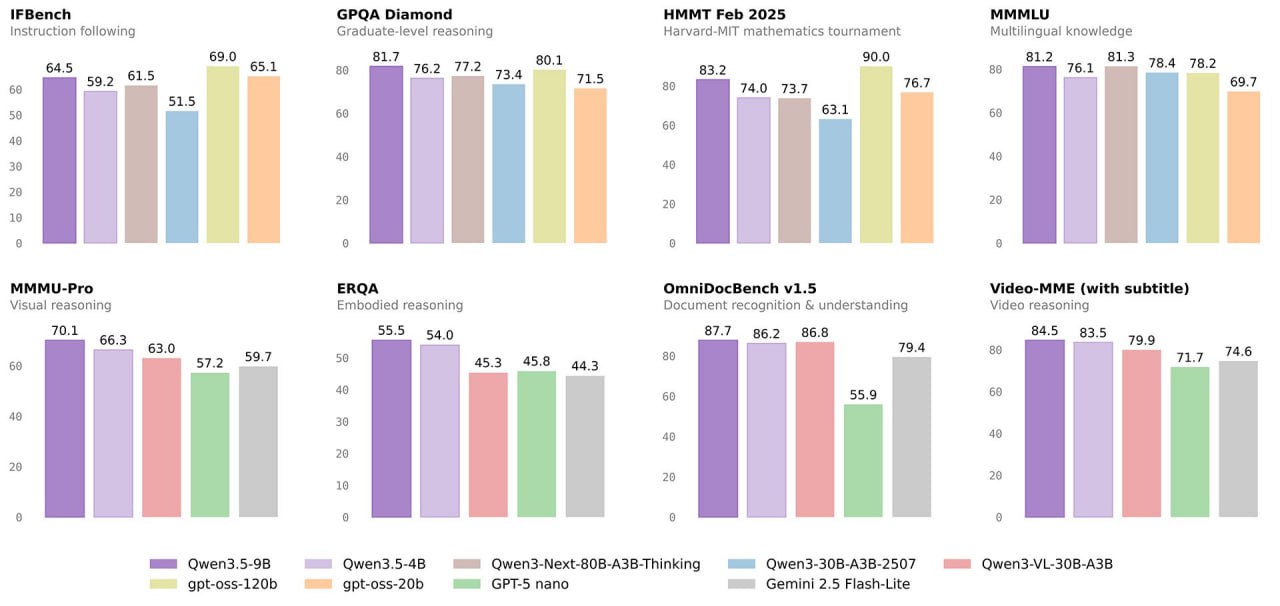
Der eigentliche Wandel
Bis vor einem Jahr war „lokal" für die meisten KMU keine realistische Option. Die Modelle waren zu schwach oder zu groß für verfügbare Hardware. Man brauchte entweder Rechenzentrums-Hardware oder akzeptierte Qualitätseinbußen.
Qwen 3.5 ist ein Datenpunkt in einer Reihe, die zeigt: Diese Grenze verschiebt sich schnell. Ein 9B-Modell, das ein 120B-Modell schlägt — auf einem Gerät, das in jedes Büro passt.
Für Teams mit vertraulichen Daten, vorhersehbaren Workloads und dem Interesse an Kostenkontrolle ist das heute eine ernsthafte Option — keine Bastlerlösung.
Nächster Schritt
Was kostet lokale KI-Infrastruktur für Ihr Team?
Bevor Sie entscheiden, lohnt sich eine konkrete Kalkulation: was kostet lokale Infrastruktur für Ihr Team — im Vergleich zu laufenden API-Kosten?